1. 제가 좋아하는 사람이 있습니다. 이 사람이 목소리 연기가 꽤 괜찮아서 어쩌다보니 목소리 데이터를 모을 수 있었습니다. 다만 쓸 만한 것이 다 합쳐서 2시간이 될까 말까 합니다.
2. 그리고 Tacotron이란 것이 있습니다. 딥러닝을 사용해서 일종의 TTS를 만드는 프로젝트인데 한국어 Tacotron이 오픈소스로 꽤 잘 나와 있습니다.
https://github.com/hccho2/Tacotron2-Wavenet-Korean-TTS
소스가 올라온지 2년 정도 되긴 했지만 제가 fork해서 일단 필요하면 계속 발전 시킬까 생각은 하고 있습니다. 기존 프로젝트에서 Requirement만 일단 모아놓고 추후에 가능하면 Tensorflow 2.x 로 가능할지 찾아보고 있습니다. 물론 제 성격상 언제 할 수 있을지 아무도 모릅니다.
3. KSS 데이터셋이라는 것이 있습니다. 한국어 음성 딥러닝을 공부하는 데에 있어서 정말 눈물나게 고마운 데이터입니다. 어떤 성우분인지 모르지만 12시간 분량의 문장을 녹음해 주었습니다.
https://www.kaggle.com/bryanpark/korean-single-speaker-speech-dataset
이걸 기반으로 음성인식도 하고 반대로 TTS도 만들고 하는데 쓰입니다. 연구소나 학교에서 정말 유용하게 쓰입니다. 대신
CC BY-NC-SA 4.0
이것 때문에 상업적인 이용은 불가능합니다.
그래서 위의 것을 다 합치면 무엇이냐...
Tacotron을 사용해서 제가 좋아하는 사람의 목소리를 TTS로 만들고 싶었습니다.
그래서 처음에는 제가 가지고 있던 2시간 분량의 좋아하는 사람의 목소리를 학습 시켜보았습니다.
결과는... 말을 하다 맙니다. 그래프를 보니 희미..합니다.
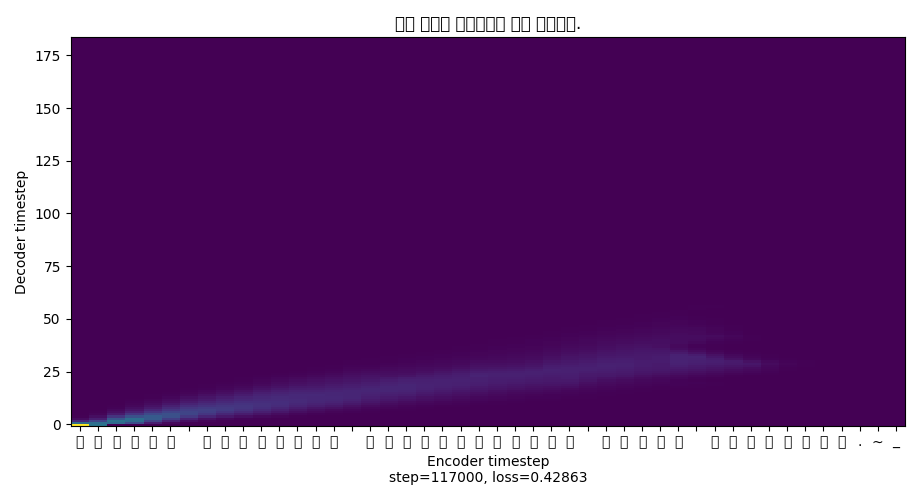
그래서 들어보니 한마디 나오려다가 옹알이를 합니다.
해결방법은 더 많은 학습데이터를 쏟아부으면 된답니다. 그런데 녹음을 부탁하기가 좀 껄끄럽습니다. 바쁠 수도 있고요.
그래서 다른 방법을 찾아보니 잘 만들어진 데이터셋과 함께 학습을 시키면 적은 데이터로도 괜찮은 품질이 나온다고 합니다.
그래서 Multi로 KSS데이터셋을 사용해 KSS와 그분의 목소리를 함께 학습을 시켰습니다.
결과는... KSS데이터셋으로 한 것만 멀정히 말합니다. 그런데 해당 학습 모델에서 KSS와 제가 모은 그분의 목소리가 섞이는 것이 보이더군요.
그분에게 제 TTS데이터를 보내봤습니다. 반응이 좋더군요. 자기 목소리랑 비슷하다고요.
근데...그거 KSS에 살짝 본인 목소리 데이터를 첨가한겁니다. (KSS12시간+그분2시간)
그래서 살짝 발상을 전환해서 제 데이터에 KSS데이터의 1시간분량을 첨가해봤습니다...
결과는... 꽤 만족스럽습니다. 전보다 발음도 괜찮고 일단 alignment는 잘 잡습니다. 대신 데이터셋을 새로 구성해서 처음부터 다시 학습 중입니다...
현재 데이터셋 설정
1. Multi-Speech
2. KSS Speech 12Hour
3. 그분+KSS 1hour
일단 현재는 만족
'기타 삽질' 카테고리의 다른 글
| SCRCPY 구동(안드로이드 미러링) 리눅스 이미지를 만들어 보았다. (1) | 2021.04.02 |
|---|---|
| 라즈베리파이에 Tensorflow를 직접 설치하기 (6) | 2021.03.01 |
| 굉장히 작은 리눅스 Tiny Core Linux (0) | 2021.02.08 |
| 추억의 게임을 리눅스에서 돌려보았다 (1) | 2020.09.10 |
| scrcpy(안드로이드 미러링프로그램)를 라즈베리파이에서 돌려보자 (0) | 2020.09.06 |
