픽셀1은 구글포토가 무제한 업로드가 됩니다. 픽셀2는 원본 무제한은 아니지만 그래도 FHD급으로 무제한 업로드가 됩니다. 그래서 굳이 오래된 픽셀폰을 어떻게든 구해서 쓰는 사람들이 있습니다. 제가 그런경우지요.
이 무제한 구글포토를 이용하려면 새로찍을 사진들은 픽셀로 찍으면 됩니다. 그러면 픽셀에서 자동으로 구글계정용량과 아무 관계없이 업로드가 됩니다. 하지만 기존에 찍어두고 업로드가 된 것이 많으면 어떻게 할까요?
일단 업로드 했던 사진들을 싹 다운로드 받은 뒤에 픽셀로 다시 업로드 하면 됩니다. 다만 좀 복잡합니다. 그리고 사진이 너무 많으면 그것도 어려운 일이고요.
그래서 우선은 용량 큰것만이라도 픽셀1으로 업로드 해보도록 합시다. 만약 여유가 되다면 모든 사진을 다 업로드 하면 되겠지요.
우선 PC에다가 사진들을 다운로드 받는 것이 편하겠지요. 구글포토의 웹 사이트로 접속해봅시다. 물론 구글로그인은 되어있다고 가정하고요.
https://photos.google.com/
Google Photos: Edit, Organize, Search, and Backup Your Photos
Google Photos never sells your photos, videos, or personal information to anyone, and we don't use your photos and videos for advertising.
www.google.com
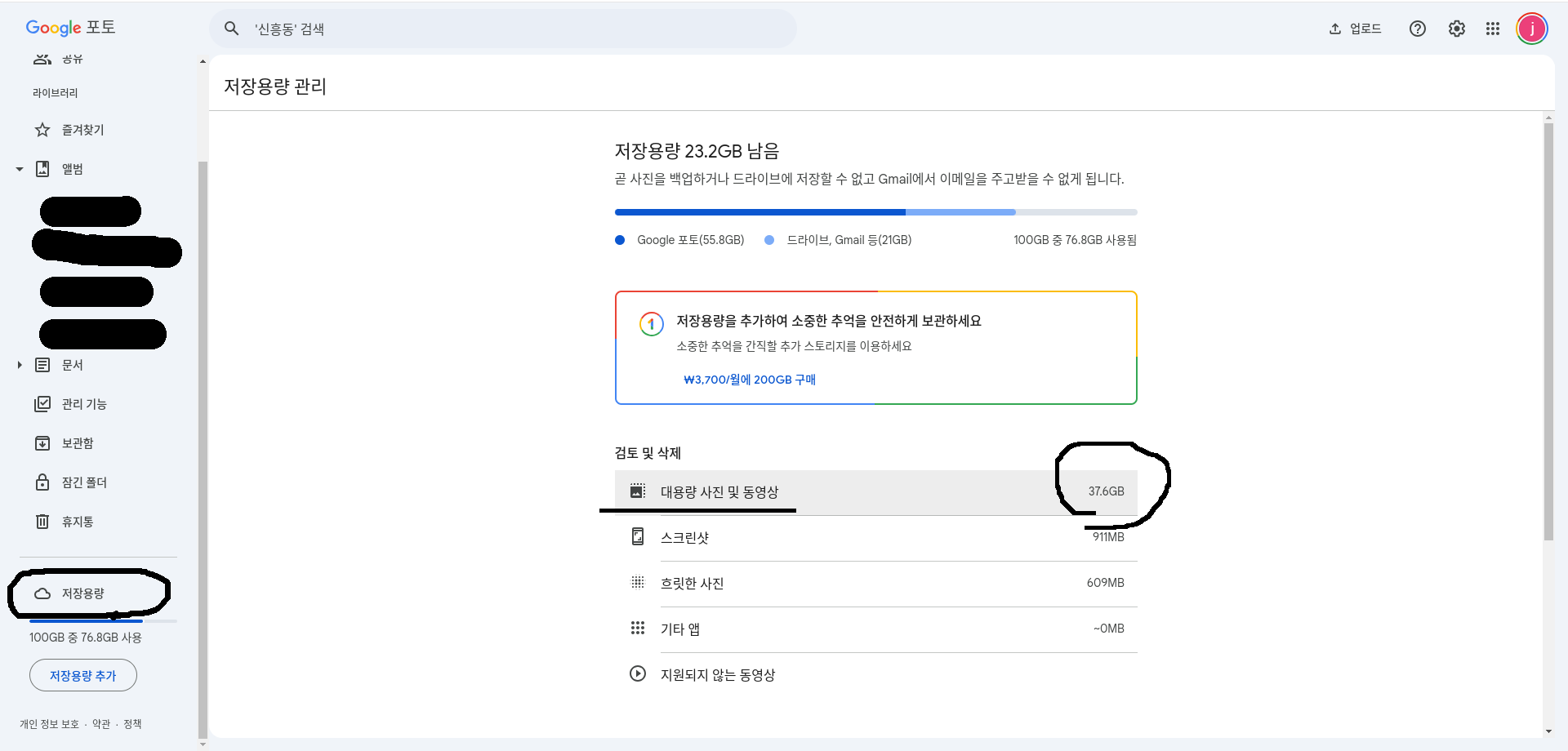
그리고 아래 왼쪽에 보면 저장용량이라고 써있는 곳이 있는데 거기를 누르면 "대용량 사진 및 동영상"이라는 링크가 있습니다.
저는 대용량만 37GB넘게 있네요. 아마 자잘한 사진까지 다 합하면 용량은 더 어마어마 할겁니다.

저 안으로 들어가면 이렇게 언제 업로드 되었는지, 얼마나 용량이 큰지 알 수 있습니다. 이걸 전부 다운로드 받아봅시다.

눈에 보이는 동영상이나 사진을 선택하면 오른쪽 위에 "모두 선택"이라는 버튼이 보입니다. 모두 선택을 하고 다운로드 버튼을 누르고 오랜시간 기다리면 zip파일 형태로 다운로드 됩니다.
다운로드가 완료되면 구글포토에서 해당 영상을 모두 삭제합니다.
오른쪽 위에 "휴지통으로 이동"을 누르면 되겠지요. 그리고 휴지통에 사진을 모두 없애야 합니다. 휴지통에 사진이 한장이라도 있으면 픽셀로 업로드 해도 그냥 계정용량을 잡아먹더군요.
따라서
왼쪽 메뉴의 휴지통으로 들어가서
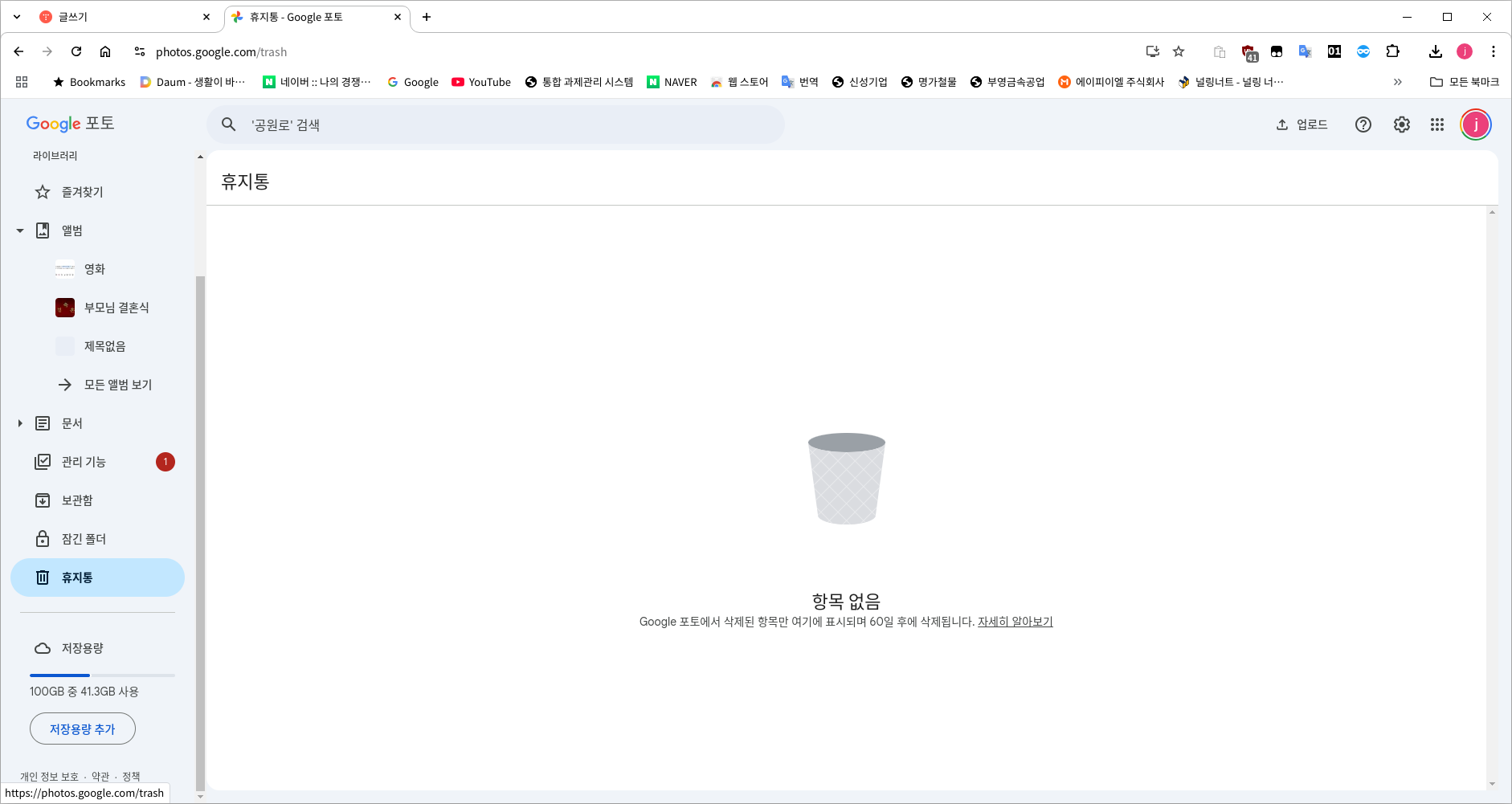
휴지통 비우기를 통해 휴지통까지 싹싹 비워주세요.
이제 픽셀의 구글포토를 한번 초기화 해줘야 합니다.

참고로 위 스크린샷은 삼성OneUI입니다.
픽셀은 조금 다릅니다. 실수로 OneUI의 것을 올렸군요.
픽셀의 앱정보로 들어간 다음 저장공간으로 들어간다음 캐시삭제와 데이터삭제를 눌러서 구글포토 앱을 초기화 해줍니다. 이거 안 해주면 동기화되면서 정상적으로 백업이 되지 않습니다.
이제 다시 PC 에서 픽셀에 영상과 사진을 USB를 통해 전송해주거나 기타 여러방법으로 넣어줍니다. 픽셀은 앱정보가 완전히 초기화된 상태이기 때문에 새로들어온 사진들을 백업하기 시작합니다.
제대로 안 된다면 구글포토 앱 자체를 다시 한번 초기화 해주세요. 제일 좋은건 지웠다가 다시 설치하는거지만 구글픽셀은 아시다시피 기본 탑재라서 앱정보에서 초기화해주는게 최선입니다.
모두 픽셀로 정상적으로 업로드 되었다면

이렇게 아래에 계정 스토리지의 공간을 차지하지 않는다고 뜹니다.
이제 픽셀1을 구입한 이유가 완전해 지는 것이지요.
'기타 삽질' 카테고리의 다른 글
| PC용 프로그램을 모바일로 이식할때 생각해야하는 것 (0) | 2025.04.07 |
|---|---|
| JMS578 펌웨어 삽질기 (0) | 2025.03.22 |
| 키보드 커스텀에 맛들리면 안 되는데... (6) | 2024.11.13 |
| ffmpeg-python 패키지 사용시 오류 문제 (3) | 2024.09.12 |
| fairseq 모듈을 Pyinstaller로 패키징시 오류 (1) | 2024.09.07 |
