이전에 Blu-ray를 우분투에서 보기위해 makemkv라는 프로그램을 설치했던 적이 있습니다.
참고 : https://moordev.tistory.com/322
지금은 사실상 유일한 블루레이 리핑 프로그램이라고 해도 과언이 아닙니다. DVD시절에는 DVDFab, Handbrake 등 여러수단이 있었지만 Blu-ray는 이상한 DRM을 넣어놓아서 굉장히 어려워 졌습니다. (그마저도 재생을 방해하는 수준입니다.)
심지어 4k 시대에 들어오면서 DRM이 너무 심해져서 그냥 4k BD대신 넷플릭스를 권할 정도가 되었습니다. 그렇지만 넷플릭스에 비해 워낙 화질이 좋다보니 BD로 나오면 이쪽으로 보고 싶어지는데 그냥보지 말라는 수준으로 만들어 놓아서 사놓아도 쓸 수가 없습니다. 그나마 PS5나 엑스박스정도만이 편하게 감상이 가능합니다.
이쯤되면 그냥 리핑해서 영상을 USB나 SD카드에 담은 다음 BD는 책꽂이 구석에 박아두는게 더 유리할겁니다. 그러려면 어찌되었건 리핑을 해야합니다.
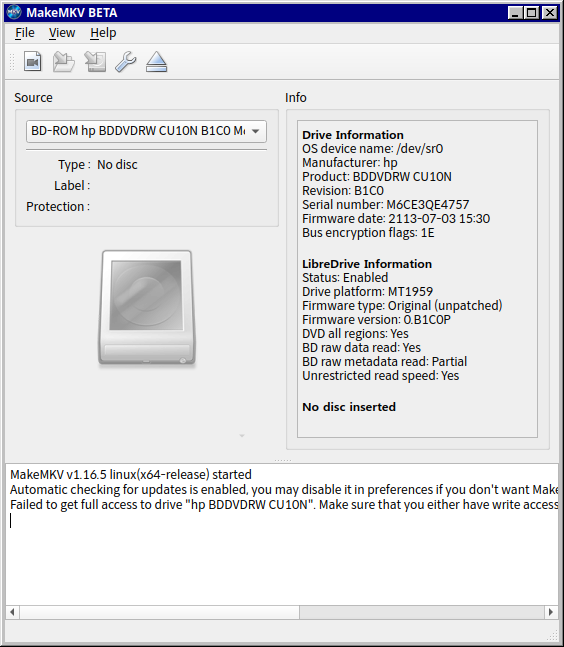
제가 갖고 있는 것은 HP노트북에 끼워주었던 CU10N이라는 BD DVD RW 드라이브 입니다. DVD나 CD는 구울 수 있지만 BD는 못 굽습니다.
그런데 모든 블루레이 드라이브가 리핑이 가능한 것이 아니라고 합니다. 심지어 기존 FHD 블루레이는 리핑이 되지만 4k는 되지 않는 경우도 있고 그냥 최신 DRM이 지원이 안되서 BD재생은 폼인 경우도 있습니다.
그래서 많은삽질이 필요한데 리핑 가능성을 보고 싶다면 MakeMKV에서 확인이 가능합니다.
오른쪽에 LibreDrive Information을 보면 알 수 있습니다.
다 필요없고 Status에서 Enable 되면 4k UHD도 리핑이 가능합니다.
Possible이라고 되어있으면 수정된 펌웨어를 입히는 것으로 사용이 가능합니다.
Hardware Support가 No라고 되어있으면 포기하세요.
대부분 BD Drive는 LG-Hitachi의 제품을 추천합니다. 저는 다행히 OEM제품인데도 불구하고 Enable로 되어있습니다. (아무래도 LG에서 제작한 것으로 보입니다.) 엥간하면 지원이 된다는 거지요. 특히 Drive Platform이 MT1959면 다 가능성이 있다고 합니다.
아마도 3월중에 4K BD가 하나 올 예정인데 그때 한번 이걸로 시도해봐야 할 듯 합니다.
'기타 삽질' 카테고리의 다른 글
| 옛날게임을 돌리려고 하면 일어나는 사소한 문제들 (해결함) (4) | 2022.05.14 |
|---|---|
| Chrome에서 Youtube 메뉴와 재생버튼등이 클릭이 안 될때 (0) | 2022.04.04 |
| PNG파일을 압축하자 pngquant (1) | 2022.01.31 |
| CR1632 배터리가 없으면... (0) | 2021.12.30 |
| Renpy 6.xx 버전 안드로이드 빌드를 위해선... (0) | 2021.12.05 |