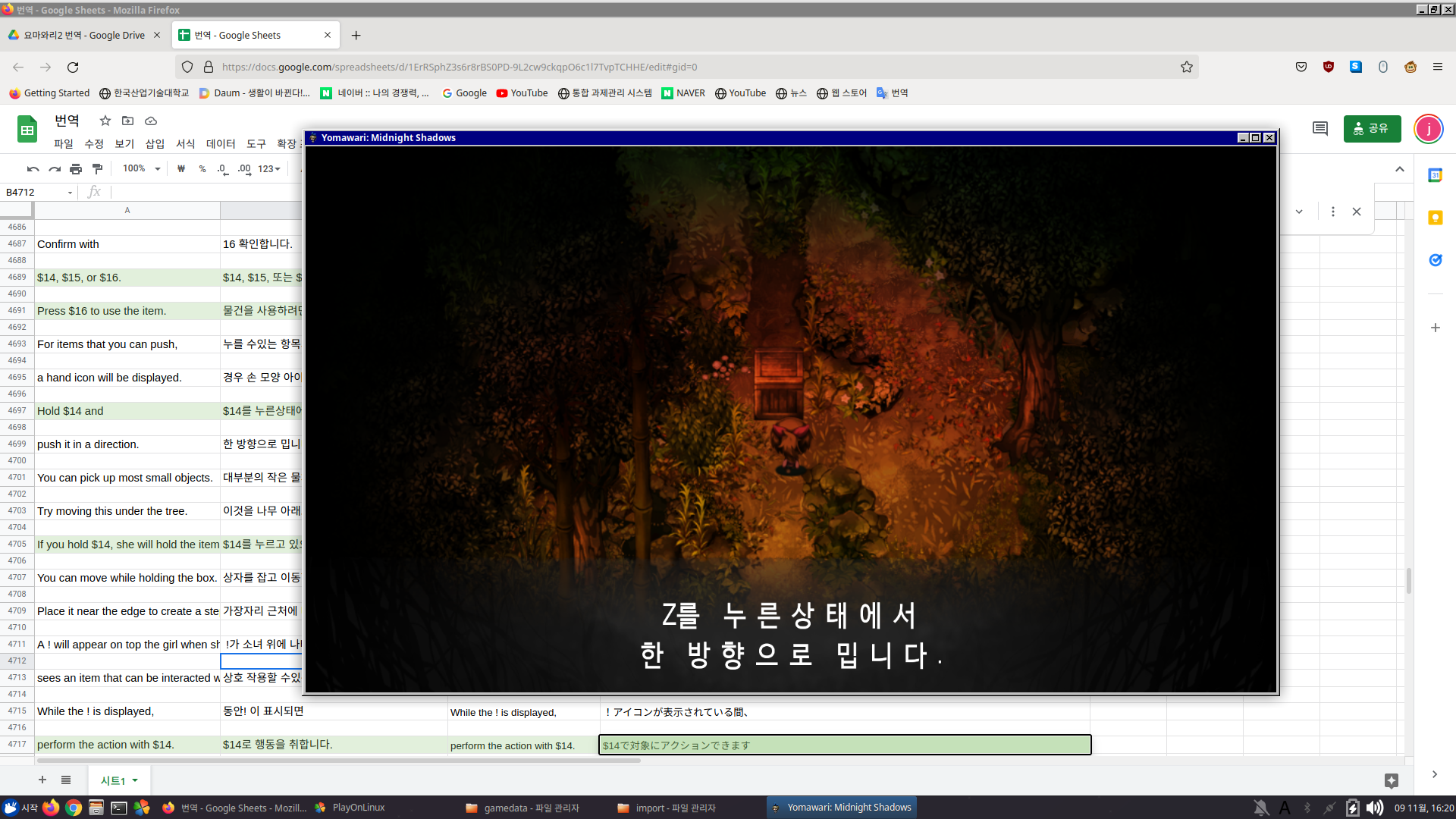
위를 보면 알겠지만 충분히 가능하다.
넵튠 리버스1 때도 그랬고 이번에 요마와리 삽질하면서 느낀게 삽질도 하다보면 는다는 것.
이야기를 하자면 좀 길다..
이게 어떻게 가능했냐면. 요마와리 1의 한글패치의 경우 중국어화 패치를 이용했다고 써있었다.
https://github.com/wmltogether/yomawari-pc-translation/tree/master/pc-tools
GitHub - wmltogether/yomawari-pc-translation: yomawari-pc-translation-project
yomawari-pc-translation-project. Contribute to wmltogether/yomawari-pc-translation development by creating an account on GitHub.
github.com
해당 소스는 여긴데 당연히 이걸로는 신 요마와리의 데이터를 휘적휘적하는 것은 불가능했다.
하지만... 헥스노가다와 기타 삽질을 통해서..
공식중 일부가 다른 것을 확인해서 수정
매직넘버라고 생각한것은 그냥 기존 dat위에 오프셋 값을 덮기만 하면 되므로 무시
pc_tools에서 text_export.py를 분석하니 오프셋값이 3바이트에 하나씩 쓰여서 0x4+0xC *i +0x4형태로 오프셋을 만드는 것이 확인 되었다.
하지만 이건 요마와리1의 경우고 신 요마와리는 오프셋값이 4바이트에 하나씩 쓰여있는 것이 확인 0x4+0x10*i+0x4로 고쳐주니 텍스트 뽑기가 무사히 된다. 단, 구조가 약간 다르므로 마지막줄에 0x00을 하나 더 삭제하면 된다. 그래도 역시 파이썬이 소스 읽기는 참 편하다.
이게 요마와리2에 맞게 수정한 파이썬 스크립트 단점이라면 파이썬2.7이라 새로 파이썬을 또 깔아야 한다는 점? (파이썬3는 기본적으로 깔려있지만 파이썬2는 지원이 끝난지 오래라 따로 깔아야 한다.)
그리고 폰트의 경우는 pc-tools폴더에서 font.csv파일을 열어서 내가 원하는 TTF 파일로 수정하고(개인적으로 나눔시리즈들이 참 좋은듯) csv_list.txt에 KS X 1001 문자 전체를 다 때려박아서 한글을 지원하면서 몇가지 특수문자도 지원하게 한다.
그리고 NISFontBuilder.exe 돌려버리면 import 폴더에 짠하고 폰트파일이 들어가니 이걸 이용하면 쉽다.
이제 남은건 번역과 이미지 수정뿐.
우선 이미지 수정은 귀찮기도 하거니와 딱히 필요하지 않으면 영문판 이미지 그냥 사용할 생각이다. fad 파일 뜯으면 된다고 하는데 귀찮은건 귀찮은거다. 이미 플레이스테이션이랑 스위치로 한글판 다 했을테니 그냥 내 흥미 본연의 이유로 하는 것.
현재는 구글번역기 돌려서 그걸 때려박았는데 좀 웃긴 결과가 나오는 중. 역시 번역은 손번역이 최고다.
https://github.com/MoorDev/shin-yomawari-pc-kr-translation-project
GitHub - MoorDev/shin-yomawari-pc-kr-translation-project: shin yomawari-pc-kr-translation-project
shin yomawari-pc-kr-translation-project. Contribute to MoorDev/shin-yomawari-pc-kr-translation-project development by creating an account on GitHub.
github.com
현재까지 작업물은 여기에 다 때려박았다.
가져가서 쓰실분은 쓰시고 바이트 단위로 삽질하는거 구경하고 싶으면 직접 해보시길
'기타 삽질' 카테고리의 다른 글
| 재미있어 보이는 머신러닝 툴킷을 발견했다 (0) | 2021.11.17 |
|---|---|
| 신 요마와리 : 떠도는 밤 심연(Yomawari:Midnight Shadow) 한글패치 선행공개 (3) | 2021.11.14 |
| cannot enable executable stack as shared object requires: Permission denied - 이게 무슨 소리지? (0) | 2021.11.02 |
| Spacedesk 엄청난 물건이군요 (0) | 2021.10.24 |
| [Windows] HDMI로 연결한 후 특정게임을 전체화면으로 돌리면 소리가 안 나온다 (0) | 2021.09.07 |